11.6.2025
Deep Dive: Memory + AI




The following is an essay written by Jordan Crook, in collaboration with John Borthwick and Jon Chin. It is a continuation and distillation of our thesis development around AI + Memory. Other related content is below.
Deep Dive: Memory + AI
When it comes to the relationship between memory and AI, I'm increasingly convinced that the truest point of leverage is that of agency and curation.
Who, or what, curates memory? How?
The architecture of memory in AI apps, agents and services is fundamental to how a product can reason, how personalized it can be, and how it can integrate into a multiplayer (multi-human) environment. Eventually, I'd guess, architectures around that will converge and just a few methods will remain, tried and true.
What will be left, however, is the curator. Who, or what, directs attention? What curates memories into long-term memory, and determines how/when those memories are retrieved? When should those memories be merged with others, or overwrite older memories?
These questions are fundamentally important because memory (both in life and in our technology) is the lever by which fundamental needs are met.
● Memory is community – there are three versions of every story: yours, mine, and the truth. Collective memory, perspective-based memory... These influence the way we interact, collaborate, compete, and advance as a social species.
● Memory is identity – we don't treat all memories equally. The memory we promote into our long-term memory powers our decisions, our perception of ourselves, and is fluid enough to be overwritten by new hyper-influential memories. Sometimes we do this manually, through writing and repetition, and sometimes these memories are promoted organically via strong emotional resonance.
● Memory is complex reasoning – for all intents and purposes, it is the complex system that powers (and bridges the gap between) System 1 and System 2 thinking.
Before delving deeper, let's take a moment to focus on how memory works in the human mind.
Human Memory
Most people think of memories as video recordings stored in specific locations, like files on a computer. But memories are actually distributed representations—patterns stored across interconnected neuron groups.
Your brain stores patterns. When triggered, these patterns are reconstructed, not replayed.
Humans forget roughly 60 percent of learned information within 24 hours. This isn't a bug—it's an evolved mechanism that prevents cognitive overload and enables social function. Storytelling, which consumes about 40 percent of conversation time, helps construct memory for both the teller and listener.
It’s these stored patterns, representations of reconstructed fragments of experience, that allow us to think both intuitively and deliberately.
To be frank, the brain is a relatively underexplored organ. I am also not a neuroscientist. So this is my very rudimentary understanding of the theoretical. But here are the basics:
● Encoding - The senses process information. Through some combination of attention and emotion, your brain determines what is worth storing. (Consider carefully just how many inputs your brain experiences a day, uncountable bits of information. Attention is piqued by novelty and strong emotional responses, helping the brain prioritize some of those inputs over others.)
● Storage - The firing of neurons and the connections between those neurons form patterns in the brain. These are the distributed representations that are stabilized over time, weighted differently, and stored.
● Retrieval - This isn't necessarily about rewinding a video and pressing play. If it were, we'd all have perfect and objective memories and eye-witness testimony would be reliable. Your brain, given the right stimulus or command to recall, tries to stitch together those fragments and patterns to generate the memory.
Via those oversimplified steps, we then have three types of memories:
- Short-term/working: The mental scratchpad for what you're doing right now —holding a phone number, following directions.
- Long-term: facts and episodes. Facts (semantic) are like reference books; episodes (episodic) are personal stories with time and place.
- Procedural: Skills—riding a bike, typing—handled by deeper systems like the basal ganglia and cerebellum; once learned, they're sturdy.
The concept that memories exist as stronger or weaker connections between neurons, which can be strengthened or weakened over time, is not dissimilar to knowledge trained within LLMs.
LLM's Memory
LLMs don't technically 'remember' things as you'd imagine, with data stored in some database and then retrieved.
Rather, LLMs have knowledge as encoded in their parameters – an absorption and compression of vast patterns and their expression. You could think of it as general knowledge, or knowledge about a world.
This parametric knowledge is accessed and activated when an LLM is prompted – the prompt acting as working memory injected at inference time.
Again, this may be quite obvious, but it's worth saying in a simple way:
LLMs don't store facts explicitly or symbolically. If they did, they'd simply be a kind of search engine. So, when a body of knowledge is thin or conflicting, an LLM's probabilistic response is just that. Probabilistic. And when a fact is well-known and well-established in its weights, an LLM will get it right the vast majority of the time (and still sometimes get it wrong, though more improbably).
But regurgitating well-established facts is the lowest hanging fruit of this technology. LLMs excel at histories and chronologies, summarizing known texts, technical documentation, and identifying examples. They are excellent researchers, copy editors, and organizers of vast, unstructured data.
But they struggle to reason against novel problems. They perform poorly on tasks outside of their training distribution.
So in the case of an agent that's meant to approach novel problems with autonomous solutions and actions, or in the case of a copilot that's meant to understand the nuances of an individual person or business and help them strategize or problem solve, most default LLM implementations as they exist today don't meet the bar.
If the next frontier of AI is to be more powerful (more personalized and less generic), it will be so because of architectural thoughtfulness and diligence in memory.
Machine Memory Architecture
AI systems currently operate with roughly four levels of memory:
- Short-term: session-based context maintenance
- Long-term: user personalization across extended timeframes
- Working memory/Chain of thought: logical sequence construction within single actions
- Tool-based: external memory via vector stores, file search, computer access
Sound familiar?
All of these exist in a similar ‘currency’, which is tokens. And tokens exist in a network of relationships with all other tokens in a sequence. As you increase the length of a context window, the connections between all those matrices add computational complexity.
This computational complexity is reflected back financially, as well (marginal tokens in a prompt are more expensive).
But when you boil it all down, we’re really just talking about information that you can do math with. Human working memory and episodic memory and LLM-based parametric knowledge and prompting… they’re all just bits of information that must be put in the context of other bits of information.
Like the human brain, not all of that information is treated equally.
Claude Code actually lets you open up its brain and see what’s being loaded into the full context window each time you press enter. To do something new, it must load the entirety of the existing context to calculate its response.
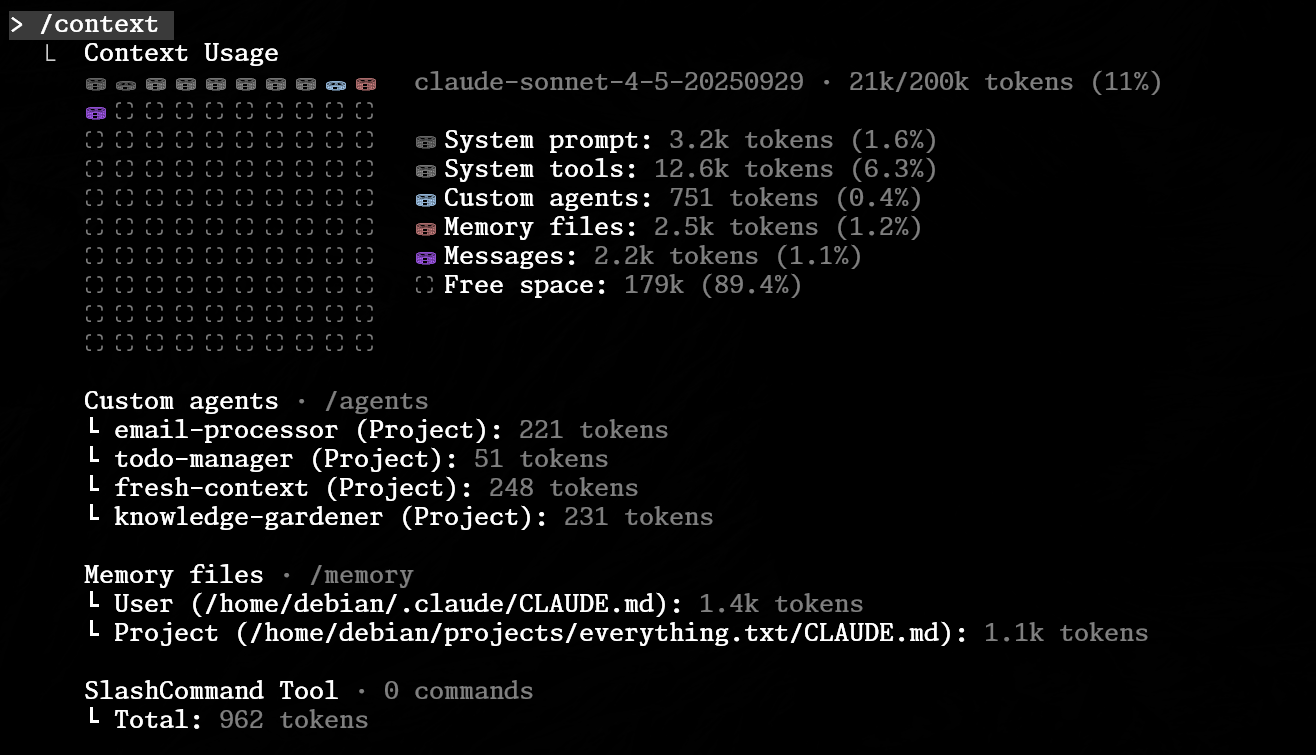
You can see that the system prompt and tools take up a pretty large chunk of context right off the bat. Meanwhile, custom sub-agents and personal memory files can take up much less space, giving developers a lot for a little.
It doesn’t take much active use for the context window to fill up.
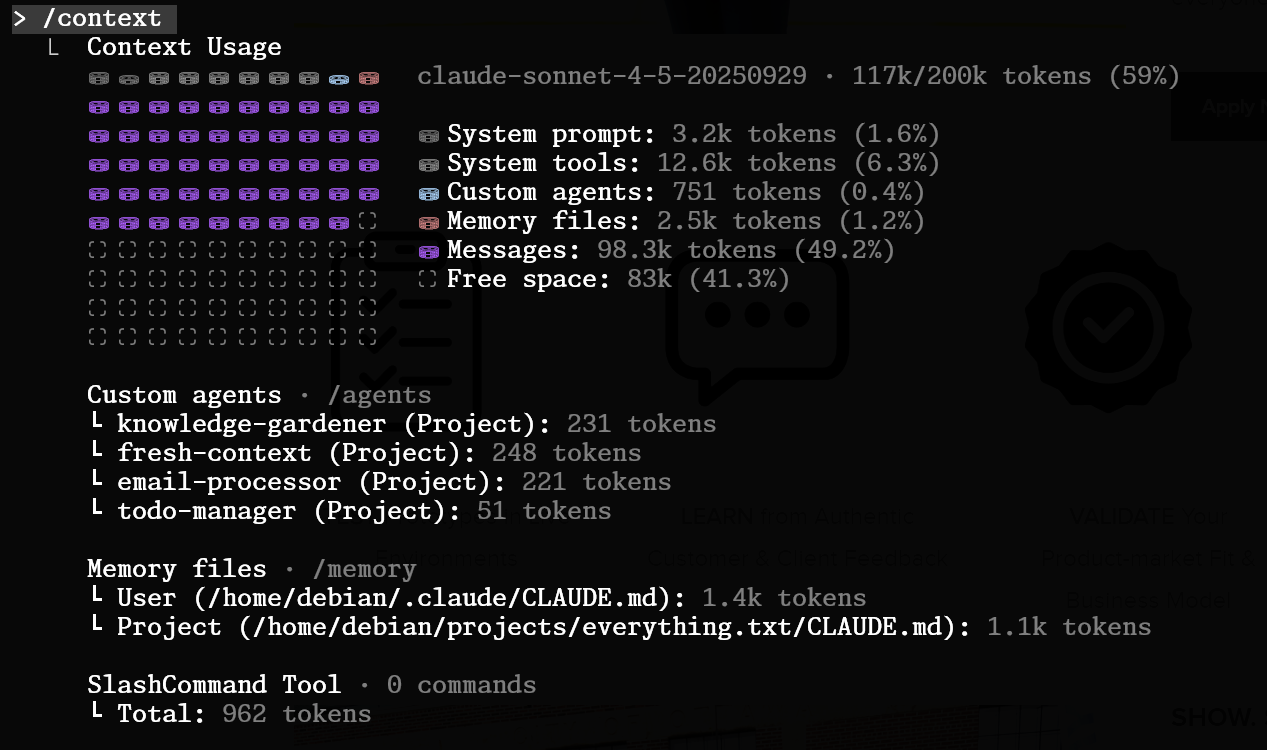
The capped context window of most LLM systems creates an environment where the system must actively manage this small patch of mnemonic inventory so it doesn’t saturate.
So many memory systems compact that long context into periodic summaries by reasoning over everything in the history of that interaction. It then sticks the summary back into the context. This is not unlike the human mind, which ‘forgets’ quite a bit while sleeping, committing far less to long term memory.
But even with diarization and compaction, both the context window and the attention mechanism are finite.
The Canary in the CoaLLMine
Jon Chin, in his adventure to build his personal AI system, has come up with a clever reliability test around memory and context saturation with these models. You, reader, may have noticed the sycophantic nature of these LLMs. One example: Claude really likes to say the word “Perfect!”
JC has lodged deep in its system prompt the mandate for it to respond with ‘okok’ instead of “Perfect!”. This behavior is contrary to its training (and linguistically weird), and thus serves as an excellent signal that the rest of its context is preserved (which contains actually important directives about style and facts about system setup) and the reasoning can be faithful to that context. However, when Claude reverts back to “Perfect!,” JC knows that the context has been degraded and the output, both incremental and overall, is at a higher risk of underperformance.
It’s not just that the context window has been maximized, but that the system’s ability to attend to and reason over that much information is limited, as well. I’ll repeat it: Both the context window and the attention mechanism are finite.
Plenty of work is going into both extending the context window (we’ve already seen quite a step function improvement there at the foundation layer, presumably with more to come) and implementing new, advanced frameworks around attention and reasoning to handle that increased context. Moreover, work is being done both at the foundation layer and at the infra and application layer around active memory management – long context compacting/compression, retrieval, and external memory architectures – to keep barrelling forward.
Three Approaches
So what does that work look like? It's hard to think of a company within our portfolio that isn't prioritizing this thoughtfulness around memory. Some are taking a more passive approach, waiting for the model companies to solve for these context and attention limitations, while others are experimenting with new architectures to maximize the performance of their products against their own specific goals.
Before delving deeper, it’s worth stating the obvious. Whoever collects, stores and is able to leverage our memory (put differently, our data) is king. The moat around this type of personal data, both on an individual and organizational level, is invaluable. That sounds trite because the last two decades of technology investment have been mostly focused on harvesting individual private data. But I’m not just talking about that OG sensibility around personal data. This isn’t only about targeting my intent (to sell stuff/ads), modeling my persona (to sell stuff/ads), or personalizing my content (for better media upon which to sell stuff/ads). It’s about the fact that my data is the missing ingredient for novel reasoning within the parameters of specific context. To create value for the end user.
I’ll put a finer point on what that means below.
As we take a look at these three companies, we’ll ask the same three questions of each of them:
- How is memory created/curated?
- By whom?
- How is memory stored?
- How is memory retrieved?
Social Ledger
The first approach to memory is the Social Ledger approach. Representing that approach is Granola, the AI notepad for meetings.
Gokul Rajaram made a prediction several months ago that meeting notes would overtake ‘documents’ as the atomic unit of business operations.
As investors in Granola, and as a super user myself, I tend to agree. I’ve been using it since alpha build was made available to people other than the founders. Based on some back of the napkin math, I’ve had several thousand meetings on the platform.
This is highly valuable data. Granola can use it to personalize the outputs of my notes, to help me work better or faster, or to upsell me to new products in the future. They can use it to train their own models. But they can also use this data in service of novel reasoning against a problem specific to me.
But let’s go back to our core questions.
The reason that the number of meetings on the platform is so high is because Granola’s mechanism for memory capture has been bundled into an existing habit. It’s perhaps one of the more genius elements of the product.
The button that I press to ‘start a meeting’, a hovering notification symbolizing the unholy alliance between my calendar and video conferencing applications, was further commandeered by Granola.
Granola stores a few different types of data (meeting transcripts, meeting summaries, and static user profile information). Chats with the AI are not stored to be used in future chats. (To be clear, I'm distinguishing 'conversation' as a meeting transcript with another human from 'chat' as a natural-language conversation with the AI inside Granola.)
This storage structure is meant to respect the privacy of the user, but is also a relatively simple way to get good outputs without overcomplicating a system that is quickly scaling.
Granola retrieves memories by shoving as many of those stored meeting summaries into the context window of an LLM to generate the requested output.
To be frank, this is not a particularly unique architecture. In some ways, it rides on the coattails of model layer advancements and exploits ever-growing context windows—a brute force approach that slams the context window with maximum available content.
However, in the journey towards building out a team-based product, with folders and collaborators, the long-context organization of those summaries is curated manually by the users. This is helpful within the context of Granola’s brute force approach to memory retrieval – siloed slices of meetings (by person, category, etc.) can point the system in the right direction with that jam-packed context window. Recipes, a newly announced feature, allow the user to point the LLM in an even more focused direction, giving the user the ability to deploy ‘working memory’ against their meeting notes without laboring over their prompts.
There is a reason I decided to call this the Social Ledger approach. The word Ledger implies that there is some immutable record at the foundation of the approach, which is certainly true of Granola. That immutable record is a transcript.
Granola understands that the same meeting, with a transcript as a single source of truth, should generate a different set of notes on a per-user basis. My notes and your notes, from the same meeting, shan't look the same.
This Social Ledger approach, where a single source of truth underlies a flexible and malleable array of broadly accessible content above, is highly reflective of how memory functions in groups of humans, generally. It mirrors natural human storytelling for safety and knowledge transfer. Team features enable access to information not consumed firsthand, reflecting how we function as a social species.
How we interpret our interactions with one another, the way we follow through on our commitments to one another, and how we evaluate ourselves within the context of larger, team-wide goals is fundamental to collaboration.
Memory that is accessible to the user, that is both malleable and immutable, is integral to that collaboration.
Memory is community.
The Moleskine
Another approach is one that I call the Moleskine approach. Representing this approach is a Fund 3 company called Sandbar.
The TL;dr on Sandbar is that it has developed a hardware interface and a piece of software that facilitates a low-friction way to have a conversation with an LLM. The goal of the software is to both organize your thoughts/ideas/memories based on category and connection. The other goal of the software is to use an LLM to expand your thinking (to provoke deeper ideas and branched concepts) via voice conversation.
Stream, by Sandbar, must foster an environment where you're willing to share anything that's on your mind, and cognitively partner with AI for to-do lists and large-scale projects, alike. It’s where you share your hopes, fears, goals, and (most importantly) your ideas, where you're able to stay organized against those things while maintaining the flow state of stream of consciousness creativity.
The Moleskine approach puts memory curation in the hands of the user. This happens because the user explicitly asks the system to remember something, or because the system has decided to tag and store something the user said (while making it visible, editable, and deletable by the user).
Sandbar uses symbolic and structured memory and eschews embeddings or neural retrieval. In other words, memories are stored in their exact symbolic form and look more like a database entry, which can be retrieved explicitly using tags or keys.
These facts are retrieved manually by the user or based on some rule system around time, topic, label or other key to use as context. That context is ephemeral and not stored.
The downside to this approach is that the system can't use an explicit memory to reason probabilistically about the user. If I say that I like spicy food, it may not be able to infer that I dislike bland recipes. But that is a trade-off the product is willing to make for the sake of user trust and transparency.
Why did StealthCo choose this approach?
The target audience is IP-protective creatives—artists and thinkers with valuable intellectual property who need thought partnership (powered by AI) without outsourcing their thinking to the AI. The LLM organizes and retrieves but doesn't interpret. A single misrepresented idea breaks trust entirely.
Though a good deal of our long-term memory is stored due to an emotional or extreme response to stimuli (these memories are referred to as 'episodic'), other long-term memory (semantic) is manually curated. We study for tests. We repeat the lyrics. We memorize multiplication tables and use flashcards to recall historical dates. We take notes.
I call this the Moleskine approach because, metaphorically speaking, you can think of this product as the intelligent librarian whose only book is your journal. This librarian can flip to the right page when you’re looking for something, will help you add new entries or delete old ones, and (when you want) will ask you provocative questions to help expand your ideas. This librarian won’t proactively start making notes in your journal of their own volition.
When we curate our memories in this way, as we would in our own journal, we make decisions around what we believe. These shifting, but closely-held, beliefs are the basis for our expectations about the world around us. And those beliefs and expectations determine our behavior and influence our decisions.
And what are we if not a pile of memories, beliefs, and behaviors?
Memory is identity.
Cognitive Partner
The Cognitive Partner approach to memory is perhaps the most sophisticated and complex that I’ve come across thus far. Representing that approach is a company that has yet to launch called Opponent Systems.
Opponent is a real-time virtual companion powered by AI and a memory system. It is meant to be used by children, via FaceTime, and the core loop of the product is that the virtual companion (Dragon) challenges the kids and tells stories.
There are several pillars upon which Opponent is built. One critical pillar is FaceTime as a distribution mechanism. There are plenty of GTM and growth benefits to a product that is, in essence, a phone number. But the experiential merit is perhaps more important. We have an expectation as humans, both young and old, that whatever is on the other side of a FaceTime is a real entity that exists in the world. Preserving that is existential to the company.
In order to do so, Opponent must develop a system where Dragon does what real entities are able to do:
- Participate in natural conversation (low latency)
- Remember the 'nouns' (people, places, things) from past and current conversations
- Reason against novel problems or concepts (while maintaining that memory and low latency)
This is non-trivial.
Simply jamming the context window with past conversations, or even summaries of past conversations, and crossing their fingers is an approach that’s entirely off the table. Even if it was precise enough to retrieve memories and respond contextually in conversation, it would be as slow as molasses. And let’s not forget that the ICP is an impatient kid.
The solution is the Cognitive Partner approach.
In essence, this approach to memory encodes facts into symbolic graph structures that include rules and relationships. The system then runs targeted traversals to generate compact 'mental maps' of those facts, rules and relationships that can be reasoned over in a way that aims to mimic System 2 thinking.
Ian (the founder) says: "Memory for static retrieval is a known problem - computers have been doing this for ages. But when it comes to a living agent, when it needs memory, it doesn't need rote memory of exactly what happened. It actually needs to reconstruct a mental map. The memories it's accrued and encoded are simply like a portfolio or gigantic warehouse of stuff to pull from to then construct dynamically for the problem at hand."
This approach allows for a few important benefits. First, it's simply more efficient -- it can be run mostly on CPUs rather than GPUs, which is more cost-effective and lower latency. Secondly, it's more precise about the memories it’s retrieving because facts, rules and relationships are stored as symbols with relationships. And lastly, it allows the agent to encounter a brand new problem, concept, or question (which is relatively common when interacting with a child) and reason against it in a way that makes sense and feels deeper than the generic pattern matching of most "system 1" LLM responses.
Regular symbol cleansing and mental map construction enables both System 1 (fast) and System 2 (deliberate) thinking. Purposeful forgetting—useful amnesia—may be an answer to context window limitations, mimicking human pattern reconstruction rather than video replay.
It's the same combination of intuitive and deliberate reasoning that humans use in their day-to-day life, built upon information that is stored as memory, some of which is forgotten.
Memory is complex reasoning.
Curation Agency
To be clear, this is just the beginning of these types of explorations from our founders and presumably the broader AI builder community. The need for these types of novel approaches will only grow as the primitives around interfaces expand (don't forget to come to Demo Day for our AI Interfaces Camp -- email me for an invite!) and the demand for AI products and services rise.
Which brings me back to the original question.
The human mind manages an uncountable number of inputs every day. Our five senses are collecting bits of information (un-tokenized, for now) that our brain sieves and selects from, both storing those bits, merging them with others, and invoking past memories to power all types of thinking, from focused work to daydreams.
Some of our memory storage is deliberate, but so much of it is mysterious. And, to be fair, a good deal of our actual reasoning is mysterious, too. But the processes that we’ve come to understand of ourselves have found their way, bit by bit, into our foundation models and the layers of technology that are being built on top of them.
Chain of Thought, RLHF, and other ‘reasoning techniques’ are the basis of advancements in LLM reasoning capabilities. At the risk of selling our apex species brains short, the anthropocentric approach to building these technologies is perhaps not the ‘best’ (whatever ‘the best’ actually means). In hindsight, we’ll probably look at this exploration as the medieval times of AI. After all, these systems already display superhuman capabilities.
But you’ve got to work with what you’ve got. And we’ve got a pretty fascinating, and still relatively underexplored, example of a neural network in the form of the human brain. So when I wonder aloud who will curate the memories of future AI systems, I am forced to wonder: Who curates my own?





